


Date: 2021.07.08
Writer: Seunghyeon Kim
Source: Saige Blog – Transfer Learning for Industrial Visual Inspection
Transfer learning 이란?
2012년 Alex Krizhevsky가 AlexNet[1]이라는 convolutional neural network (CNN)으로 ImageNet 데이터셋에서 기존 비전 알고리즘을 모두 압도하는 성능을 보고한 이후로 CNN은 비전문제에 매우 광범위하게 적용되고 있습니다. 하지만 기존 비전 알고리즘에 비해 CNN이 갖는 치명적인 단점이 있었는데 그것은 바로 깊은 CNN을 학습시키기 위해 매우 많은 양의 데이터가 필요하다는 것이었습니다. 이러한 문제점 때문에 초창기 CNN은 주로 ImageNet과 같이 매우 많은 이미지들로 구성된 데이터셋에만 적용되어 왔습니다.
많은 연구자들이 어떻게 하면 데이터가 적은 도메인에 CNN을 적용할 수 있을 지를 고민하고 연구한 결과 여러 방법들을 생각해냅니다. 그 방법들 중 하나가 본 글의 주제인 transfer learning입니다. Transfer learning이란 데이터가 아주 많은 도메인(source 도메인)에서 학습된 지식을 데이터가 적은 도메인(target 도메인)으로 전이(transfer)시키는 학습 방법론입니다. CNN에서 transfer learning은 주로 데이터가 적은 target 도메인 학습을 위한 CNN의 weight 값을 source 도메인에서 학습된 CNN의 weight 값으로 초기화하는 방식으로 적용됩니다. Transfer learning에 대한 아이디어는 2012~2013년에 활발히 논의가 되어 2014년에 이와 관련된 많은 논문들이 publish 되었습니다[2-7]. 이 중에서 특히 [7]에서 보고한 transfer learning에 관한 다양한 실험 결과들은 연구자들로 하여금 CNN에 transfer learning을 적용하는 방식에 대한 많은 영감을 주었습니다. [2-7] 논문들은 모두 CNN 연구 초창기에 transfer learning이라는 방법론이 정착할 수 있도록 하는 데에 많은 기여를 한 논문들이므로 한 번쯤 읽어보는 것을 추천드립니다.
Transfer learning 연구들에서 사용되는 source domain과 target domain의 유사성에 대한 고찰
2014년 이후로는 거의 모든 CNN 연구에 transfer learning이 적용되었습니다. 그런데 대부분의 연구들에서 transfer learning 적용 시 source와 target 도메인들을 서로 동일한 특성을 가지고 있는 데이터셋으로 세팅하여 사용하였습니다. 대표적인 예로는 source 도메인에 ImageNet 데이터셋을, target 도메인에 비교적 작은 데이터셋인 Pascal VOC나 Caltech-101 데이터셋을 사용하는 경우가 있습니다. 이러한 source와 target 도메인의 데이터셋들은 전체적으로 비슷한 유형의 이미지들로 구성되어 있으며 심지어 서로 동일한 클래스도 존재합니다(그림 1).
이러한 source와 target 도메인은 단지 사람이 보기에 유사하다고 생각되는 정도가 아니라 CNN에서 추출하는 feature들도 유사한 특성을 보입니다. 그림 2는 동일한 CNN에 source와 target 도메인의 이미지들을 통과시켜 feature vector를 추출한 후 PCA, t-SNE로 2차원 공간에 embedding 시킨 결과입니다. 그림에서 볼 수 있듯이 CNN은 target 도메인인 Caltech-101과 Pascal VOC 데이터셋의 feature가 ImageNet 데이터셋의 feature와 매우 유사하다고 판단합니다. 따라서 이와 같이 유사한 도메인 사이에서 transfer learning이 잘 작동하는 것은 어떻게 보면 당연한 결과라고 할 수도 있습니다.
하지만 세이지리서치에서 주로 타겟하고 있는 도메인은 제조업 도메인입니다. 제조업 도메인의 이미지들이 학계에서 주로 사용되는 ImageNet 데이터셋의 이미지들과 얼마나 다른 지를 DAGM 데이터셋[8]을 통해 살펴보겠습니다. DAGM 데이터셋은 섬유 형상 배경에 가상의 결함들을 만들어 놓은 데이터셋으로 그림 3과 같이 이미지의 외관이 ImageNet 데이터셋과 매우 다릅니다. 이미지의 외관뿐만 아니라 CNN 역시 이 두 데이터셋의 feature가 서로 다르다고 인식합니다. 위에서 설명한 방법과 동일한 방식으로 ImageNet과 DAGM 데이터셋에서 추출한 feature들을 시각화하면 그림 4와 같습니다. 그림 4의 결과를 통해 CNN은 학계에서 흔히 사용되는 Caltech-101이나 Pascal VOC와는 달리 DAGM과 같은 제조업 데이터의 feature는 ImageNet 데이터의 feature와 매우 다르다고 인식하는 것을 확인할 수 있습니다.
따라서 다른 연구들에서와 같이 transfer learning을 잘 적용하기 위해서는 우리가 타겟으로 하려는 제조업 도메인의 데이터와 유사한 특성을 가지고 있는 source 도메인의 데이터셋을 이용하는 것이 필요해 보이기도 합니다. 하지만 각 제조업체들에서 생산하는 제품에 대한 데이터는 매우 엄격한 보안 아래에서 관리되며 따라서 안타깝게도 제조업 도메인에서 ImageNet과 같이 방대한 데이터셋을 구축하는 것은 거의 불가능에 가깝습니다. 그렇다면 이러한 제조업 도메인에서는 transfer learning을 어떻게 적용해야 할까요?

그림 1. Transfer learning을 적용하는 많은 연구들에서 사용되는 source와 target 도메인 사이의 유사성
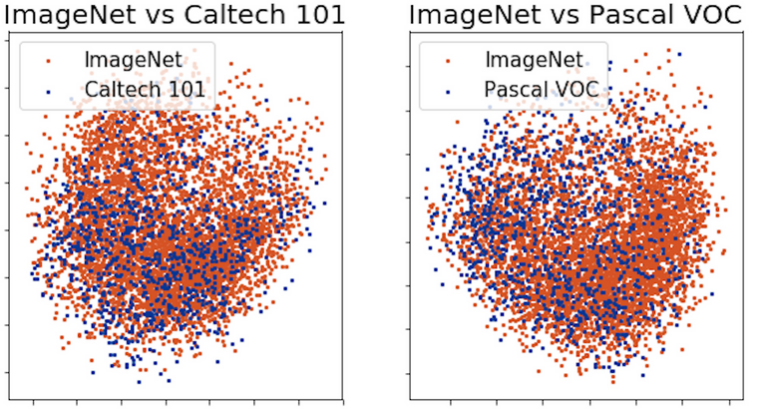
그림 2. CNN에서 추출한 각 데이터셋의 feature를 2차원 공간에 embedding 시킨 결과(위: PCA, 아래: t-SNE)

그림 2. CNN에서 추출한 각 데이터셋의 feature를 2차원 공간에 embedding 시킨 결과(위: PCA, 아래: t-SNE)

그림 3. ImageNet 데이터셋과 DAGM 데이터셋

그림 5. DAGM 데이터셋
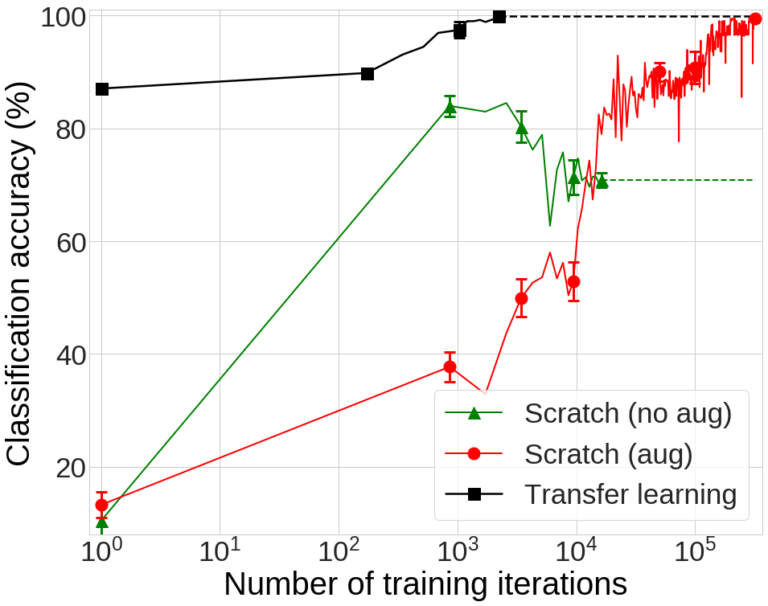
그림 6. 각 실험의 classification 성능 비교
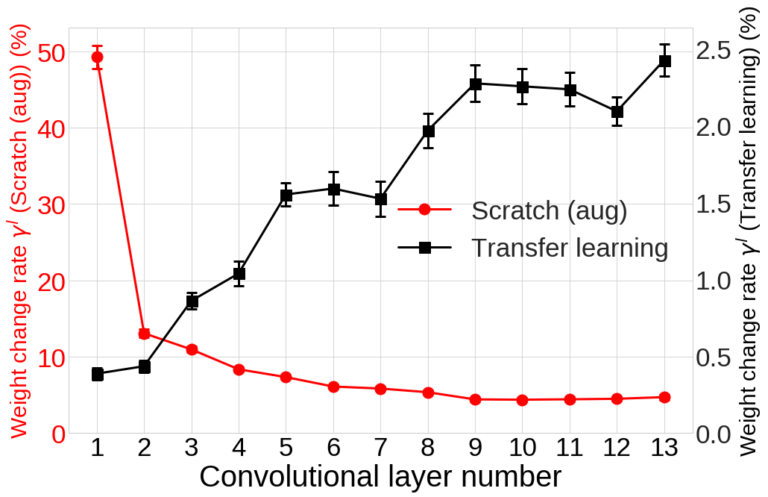
그림 7. Transfer learning과 *Scratch (aug)*의 각 layer의 weight 변화율
Transfer learning for industrial visual inspection
결론부터 말씀드리면 transfer learning은 source와 target 도메인의 특성이 매우 다를 때에도 잘 작동합니다. 즉, 제조업 도메인의 검사를 위한 CNN을 학습시킬 때에도 ImageNet 데이터셋을 source 도메인으로 선택하여 transfer learning을 적용하면 됩니다. 그렇다면 지금부터는 서로 전혀 다른 source와 target 도메인 사이에 transfer learning을 적용했을 때 CNN의 성능이 어떻게 변하는지, CNN에서 학습되는 feature에는 어떠한 영향을 미치는 지에 대해 살펴보겠습니다. 본격적인 논의에 앞서 다음 몇 가지 사항들을 정리하고 가겠습니다.
- Source 도메인의 데이터셋은 ImageNet을 사용합니다.
- Target 도메인의 데이터셋은 DAGM을 사용합니다. DAGM 데이터셋은 그림 5와 같이 총 여섯 종류의 섬유 재질 배경 위에 결함이 있는 데이터셋입니다. Target 도메인의 문제는 DAGM의 여섯 종류의 섬유 재질을 분류함과 동시에 결함인지 아닌지까지 분류하는 classification 문제입니다. 각 섬유 재질은 1000개의 정상 데이터와 150개의 결함 데이터로 구성되어 있습니다.
- CNN은 VGG16 네트워크를 사용합니다. 네트워크를 학습시키기 위한 optimizer로는 batch size 32, learning rate 1e-3의 SGD를 사용합니다.
- Transfer learning 방법론으로는 source 네트워크의 weight를 target 네트워크로 transfer 후 전체 target 네트워크를 재학습시키는 fine-tuning을 사용합니다 (저희의 문제와 같이 source와 target 도메인이 다를 경우 transfer된source 네트워크의 weight를 freeze 하는 transfer learning 방법론은 잘 작동하지 않으며 이에 대한 자세한 내용은 [9]에서 확인할 수 있습니다).

그림 5. DAGM 데이터셋
제조업 도메인에서 transfer learning이 CNN의 성능에 미치는 영향
제조업 도메인에서 transfer learning이 CNN 성능에 미치는 영향을 확인하기 위해 다음과 같은 세 가지 세팅으로 CNN을 학습하였습니다.
- Data augmentation 없이 target 데이터셋에 CNN을 처음부터 학습시킴: Scratch (no aug)
- Target 데이터셋에 data augmentation (rotate, flip)을 적용한 후 CNN을 처음부터 학습시킴: Scratch (aug)
- Transfer learning 적용하여 target 네트워크를 학습시킴: Transfer Learning
실험 결과는 그림 6과 같습니다. 먼저 *Scratch (no aug)*는 낮은 분류 정확도(70.87%)에 수렴하는 것을 확인할 수 있습니다. 이를 통해 DAGM 데이터셋과 같이 적은 수의 데이터로 깊은 네트워크를 학습시킬 경우 over-fitting이 발생하는 것을 확인할 수 있습니다. 이러한 over-fitting 문제는 data augmentation으로 해결할 수 있습니다 (Scratch (aug) 결과). 하지만 그래프에서 볼 수 있듯이 최종 정확도(99.55%)에 수렴하기까지 매우 오랜 시간(320k iteration)을 학습해야 하는 것을 확인할 수 있습니다. 반면에 transfer learning을 적용할 경우 어떠한 data augmentation 없이도 최종 정확도(99.90%)까지 매우 적은 학습(2,242 iteration)만에 도달하는 것을 확인할 수 있습니다.
이 실험 결과를 통해 제조업 도메인과 같이 방대한 source 도메인을 구축하기 힘든 도메인에는 target과 전혀 다른 특성의 source 도메인으로부터 transfer learning을 적용하는 것이 큰 도움이 된다는 것을 알 수 있습니다.
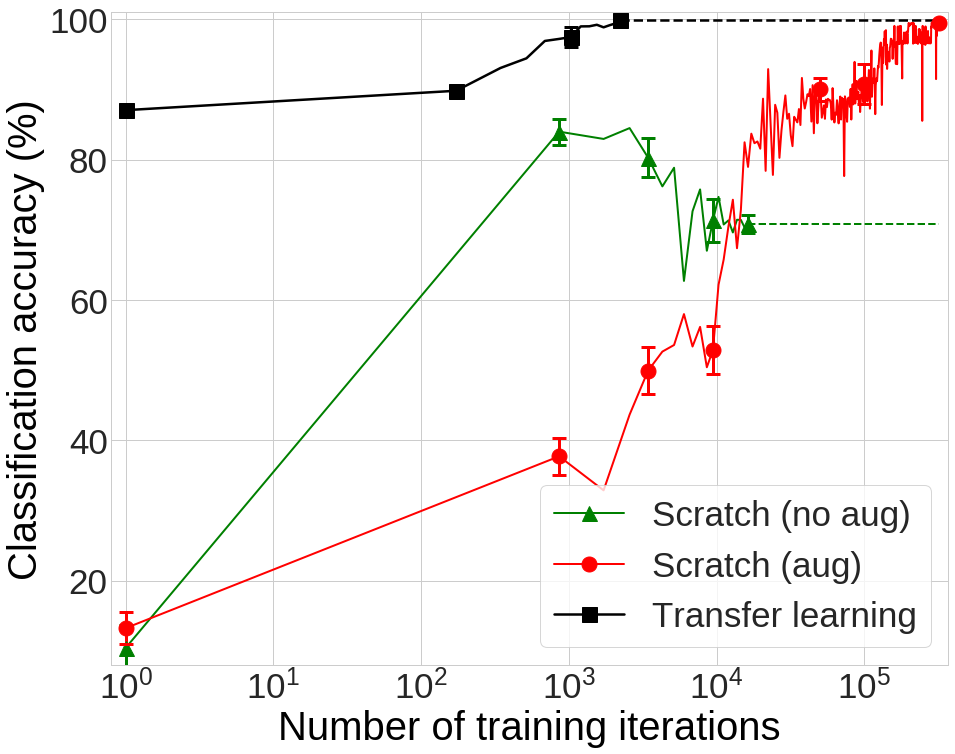
그림 6. 각 실험의 classification 성능 비교
Transfer learning으로 학습된 CNN의 특징
Transfer learning을 사용하면 저희의 타겟인 제조업 도메인에 적은 데이터만으로 CNN을 성공적으로 적용할 수 있는 것을 확인하였습니다. 그렇다면 transfer learning을 이용하여 학습한 CNN (이후 Transfer learning이라고 기술)은 어떤 특징을 가지길래 처음부터 학습한 CNN (이후 Scratch라고 기술)과 비교하여 훨씬 높은 학습 효율을 낼 수 있는 지에 대해 알아보겠습니다.
Transfer learning은 Scratch에 비해 다음과 같은 세 가지 특징을 보입니다.
- 동일한 수준의 정확도에 도달하기까지 Transfer learning에서는 Scratch보다 적은 양의 weight update가 일어납니다. 또한 네트워크의 아랫단보다 윗단의 weight update가 많이 됩니다.
- Transfer learning은 Scratch보다 더 sparse한 feature를 학습합니다.
- Transfer learning은 Scratch보다 더 disentangle된 feature를 학습합니다.
Transfer learning의 각 특징들을 살펴보기 위해 DAGM 실험에서 높은 분류 정확도에 도달한 두 네트워크 Transfer learning과 *Scratch (aug)*의 특징들을 비교 분석해보겠습니다.
1. Transfer learning은 Scratch보다 적은 양의 weight를 update 하며 네트워크의 윗단을 주로 update 합니다.
CNN의 각 $l$ 번째 layer의 weight 변화율을 아래 식과 같이 weight의 초기값 $w_{0}$과 학습이 수렴한 후의 weight 값 $w_{text{converged}}$의 차이로 정의합니다.
$$gamma^{l} triangleq frac{parallel w_{text{converged}}^{l} -w_{0}^{l} parallel_{2}}{parallel w_{0}^{l} parallel_{2}}$$
그림 7은 학습이 수렴한 후 Transfer learning과 *Scratch (aug)*의 각 layer에서의 weight 변화율 $gamma^{l}$을 비교한 결과입니다. 흥미롭게도 두 네트워크에서 weight 변화율은 전혀 반대의 경향을 보입니다. Transfer learning에서는 *Scratch (aug)*에 비해 전체적으로 훨씬 적은 양의 weight 변화가 일어나는 것을 확인할 수 있습니다. 특히 Transfer learning은 네트워크의 아랫단(1~7번째 layer)의 weight를 거의 update하지 않는 것을 확인할 수 있습니다. 즉, Transfer learning의 아랫단에서는 ImageNet 데이터셋에서 학습된 source 네트워크와 거의 동일한 low-level feature를 추출합니다 (neural network의 아랫단에서는 이미지의 edge와 같은 low-level feature들이 학습된다고 알려져있습니다 [3]). Transfer learning에서 주로 학습 되는 것은 네트워크의 윗단이며 이를 통해 source 도메인과는 전혀 다른 target 도메인의 task가 학습이 된다는 것을 알 수 있습니다.
이와는 반대로 *Scratch (aug)*는 윗단보다는 아랫단이 훨씬 더 많이 학습됩니다. 즉, CNN을 새로운 target 도메인에 처음부터 학습시킬 때는 해당 도메인에 맞는 low-level feature들을 학습하는 데에 학습의 많은 부분이 투자된다는 것도 확인할 수 있습니다.
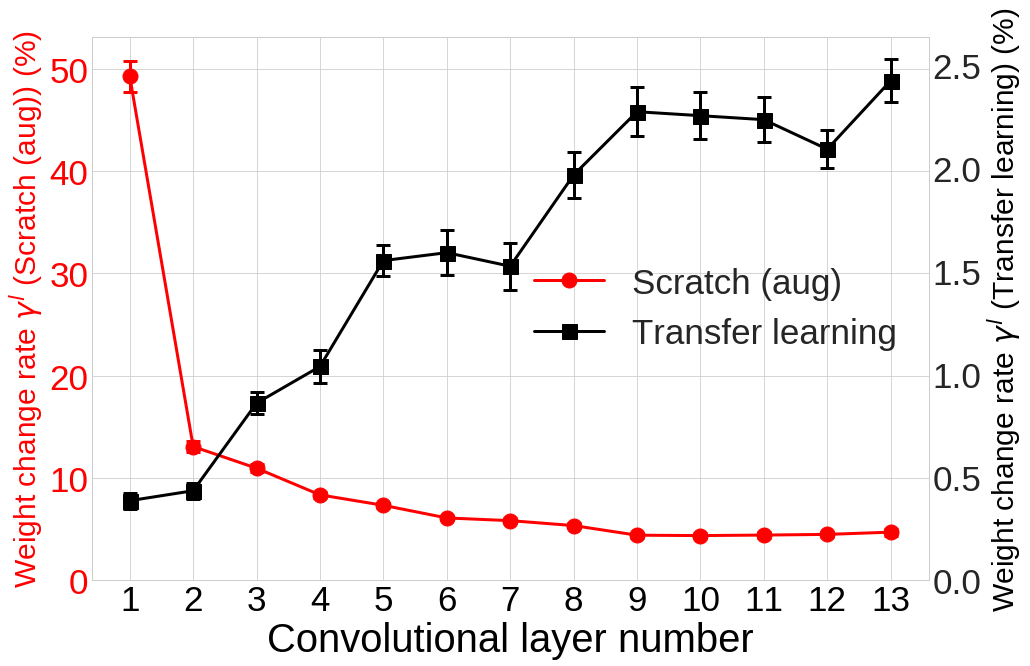
그림 7. Transfer learning과 *Scratch (aug)*의 각 layer의 weight 변화율
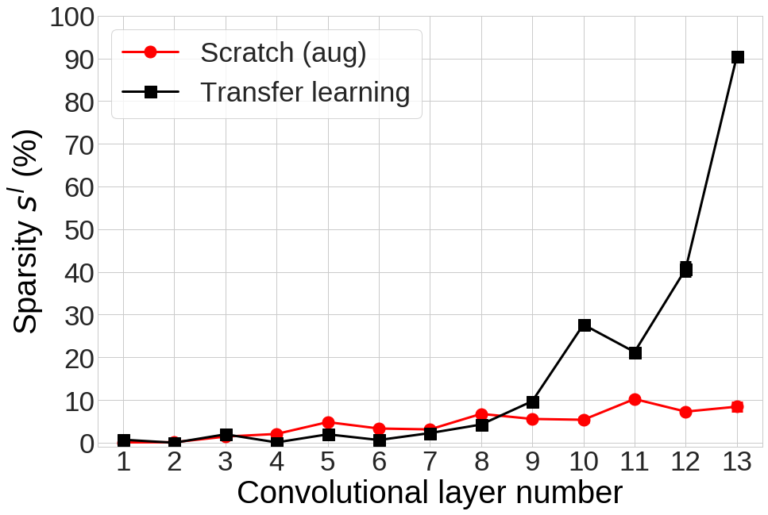
그림 8. Transfer learning과 *Scratch (aug)*의 각 layer의 sparsity
2. Transfer learning은 Scratch보다 더 sparse한 feature를 학습합니다.
CNN의 각 $l$ 번째 layer의 output feature의 sparsity를 아래 식과 같이 정의합니다.
$$s^{l} triangleq frac{text{Number of dead channels of the $l$-th layer}}{text{Number of total channels of the $l$-th layer}}$$
그림 8은 Transfer learning과 *Scratch (aug)*의 각 layer에서의 sparsity $s^{l}$을 비교한 결과입니다. Sparsity 역시 두 네트워크 사이에 매우 큰 차이가 있습니다. 먼저 Transfer learning의 아랫단 (1~8번째 layer)은 sparsity 값이 거의 0에 가깝습니다. 즉, Transfer Learning의 아랫단에서는 source 네트워크에서 학습된 매우 dense한 feature들이 추출되고 있다는 것을 알 수 있습니다. 하지만 Transfer learning의 9번째 layer부터 sparsity가 증가하기 시작하고 마지막 layer에서는 매우 급격하게 증가하여 *Scratch (aug)*의 sparsity와 비교해서 매우 큰 차이를 보입니다 (마지막 layer에서의 sparsity – Transfer Learning: 90.47%, Scratch (aug): 8.44%).
그림 9는 동일한 데이터가 주어졌을 때 *Scratch (aug)*과 Transfer learning의 마지막 convolutional layer의 output feature를 시각화 한 것입니다. 그림에서 볼 수 있듯이 Transfer learning의 마지막 convolutional layer에서는 대부분의 feature가 비활성화 되며 활성화된 소수의 feature들에서 이미지의 결함 형상을 정확하게 표현하고 있는 것을 확인할 수 있습니다. *Scratch (aug)*의 feature들도 결함 영역을 정확히 표현하고 있기는 하지만 Transfer learning에 비해 매우 dense한 것을 알 수 있습니다.
이러한 feature의 sparsity를 통해 Transfer learning의 윗단 layer들은 아랫단 layer들에서 추출되는 dense한 정보들 중에서 target 도메인에 가장 적합한 소수의 feature들을 적절하게 선택하고 조합하도록 학습된다는 것을 알 수 있습니다. 따라서 source 도메인이 매우 다양하고 방대한 데이터들로 구성되어 있기만 하면 target 도메인과 전혀 다른 특성을 갖고 있더라도 transfer learning이 성공적으로 적용될 수 있다는 결론을 내릴 수 있습니다. 또한 transfer learning은 target 도메인에 대한 새로운 feature를 만들어내는 것이 아니라 source 도메인의 정보 중 불필요한 정보들을 제거하는 방식으로 작동하기 때문에 학습이 매우 효율적이고 빠르게 수렴합니다.
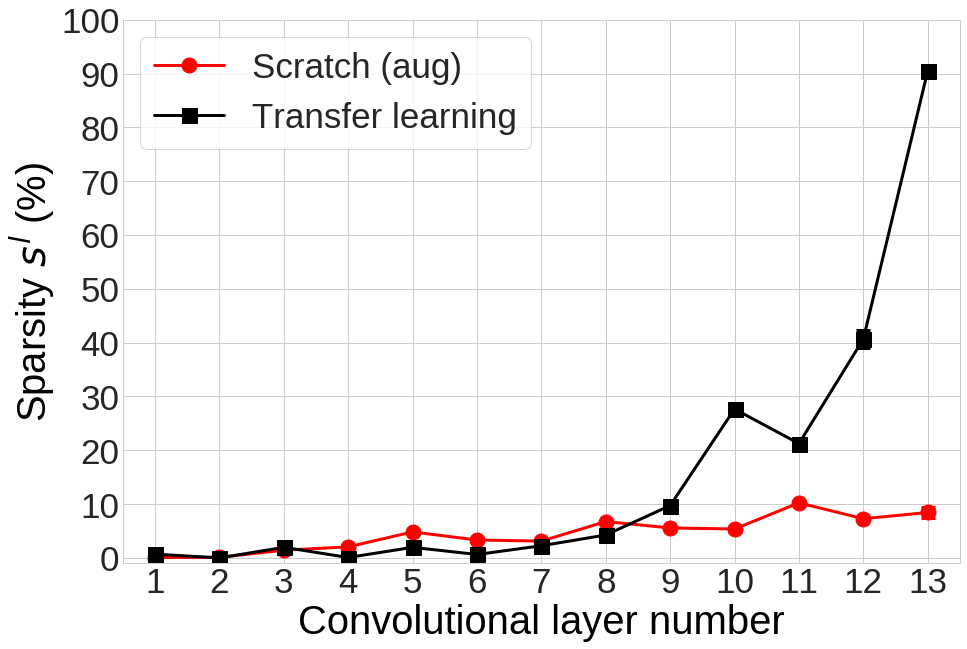
그림 8. Transfer learning과 *Scratch (aug)*의 각 layer의 sparsity
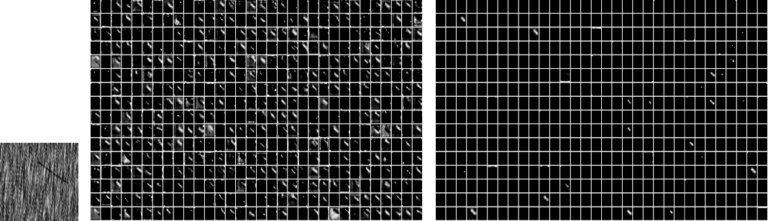
그림 9. 동일한 데이터(맨 왼쪽)가 주어졌을 때 Scratch (aug) (중간)과 Transfer learning (오른쪽)의 마지막 layer의 output feature를 시각화 한 것
3. Transfer learning은 Scratch보다 더 disentangle된 feature를 학습합니다.
위에서 저희는 Transfer learning과 Scratch (aug)가 결함의 특징을 전혀 다른 방식으로 학습한다는 것을 확인하였습니다. 그렇다면 두 네트워크가 학습하는 feature 중에서 어떤 것이 더 좋은 feature 일까요? 딥 뉴럴 네트워크가 학습하는 feature를 연구하는 여러 연구들에서 데이터를 더 많이 disentangle 하는 feature일 수록 더 좋은 feature라고 주장하고 있습니다 [11-13]. 딥러닝에서 학습되는 feature의 disentanglement에 대한 명확한 정의는 아직 없지만 많은 연구들에서 disentangle된 feature의 manifold는 flat하다는 데에 동의합니다. 따라서 저희는 Transfer learning과 *Scratch (aug)*에서 학습된 feature의 manifold가 flat한 정도를 통해 두 네트워크에서 학습된 feature들의 disentanglement를 비교해보겠습니다.
Feature의 disentanglement에 대한 정량적 지표는 [11]에서 제시하는 측정 방법을 사용하여 구할 수 있습니다. [11]에서 제시하는 정량적 지표는 feature space에서 두 점 사이의 Euclidean 거리와 geodesic 거리 값의 차이를 구하는 것입니다. 완전히 flat한 manifold에서는 두 점 사이의 Euclidean 거리와 geodesic 거리 값이 동일하기 때문에 [11]에서 제시하는 정량적 지표의 값이 작을 수록 feature가 더 disentangle되어 있다고 할 수 있습니다. 저희 데이터에서 이를 계산하는 자세한 과정은 [10]를 참고해주시기 바랍니다. Transfer learning과 *Scratch (aug)*에서 disentanglement 정량적 지표를 계산하면 표 1과 같습니다. 결과에 따르면 Transfer learning에서 학습된 feature의 manifold가 더 flat하며 따라서 더 disentangle 되어 있다는 것을 확인할 수 있습니다.
Feature의 disentanglement의 정도는 정량적 지표 뿐 아니라 정성적으로도 비교할 수 있습니다. 딥러닝 연구 초창기에 딥 네트워크에서 학습되는 feature의 disentanglement에 대한 개념을 확립시킨 유명한 연구 [12]에서는 disentangle된 feature의 여러 특징들을 정의했습니다. 그 중 하나는 서로 다른 클래스의 feature들 사이를 linear interpolation 할 때 disentangle된 feature일 수록 더 그럴듯한 형상이 나온다는 것입니다. 그림 10은 [12]의 저자인 Yoshua bengio의 강의 슬라이드이며 이러한 개념을 가장 잘 설명하고 있습니다. 즉, disentangle된 feature일 수록 feature의 manifold가 flat하며 따라서 linear interpolation 상의 점들이 manifold 위에 존재할 확률이 더 높아집니다.
이러한 개념을 저희 데이터에 적용한 결과는 그림 11과 같습니다. DAGM 데이터셋에서 Texture 1 클래스와 Texture 2 클래스 사이, Texture 2 클래스와 Texture 5 클래스 사이를 linear interpolation 할 때 그림 11의 중간 행은 *Scratch (aug)*의 feature를, 마지막 행은 Transfer learning의 feature를 시각화 한 것 입니다 (feature들을 어떻게 시각화 했는 지는 [10]를 참고해주시기 바랍니다). *Scratch (aug)*의 feature는 서로 다른 클래스 사이를 interpolation 하는 중간에 두 클래스의 결함이 동시에 존재하는 구간이 많습니다. 즉, *Scratch (aug)*의 feature는 그림 10에서 설명하는 것과 같이 disentangle된 정도가 적은 것을 알 수 있습니다. 반면에 Transfer learning의 feature는 이에 비해 interpolation 상에서 두 결함이 겹쳐 있는 구간이 훨씬 적습니다. 이를 통해 Transfer learning의 feature가 *Scratch (aug)*의 feature보다 더 disentangle 되어 있다는 것을 확인할 수 있습니다.
이와 같은 정량적, 정성적 실험을 통해 Transfer learning의 feature가 disentangle 되어 있다는 것을 확인하였습니다. 따라서 (적어도 feature의 disentanglement라는 측면에서는) Transfer learning이 Scratch보다 더 좋은 feature를 학습한다는 것을 알 수 있습니다.

표 1. 두 네트워크에서 학습한 feature disentanglement의 정량적 지표값
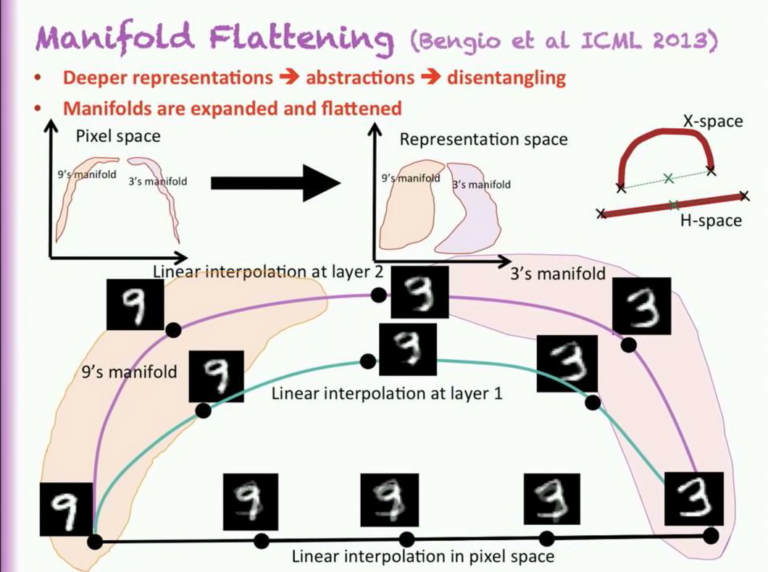
그림 10. Disentangle된 feature의 manifold에 대한 설명 (from https://www.youtube.com/watch?v=Yr1mOzC93xs)

그림 11. 서로 다른 클래스 사이를 linear interpolation 할 때 각 data space를 시각화한 결과. 첫번째 행: input space, 중간 행: Scratch (aug)의 마지막 convolutional layer의 feature space, 마지막 행: Transfer learning의 마지막 convolutional layer의 feature space.
결론
이번 포스팅에서는 세이지리서치의 타겟인 제조업 도메인에 transfer learning이라는 기술을 어떻게 적용해야하는지, 또 transfer learning을 적용했을 때 어떤 효과가 있는 지에 대해서 알아보았습니다. 세이지리서치에서는 본 글에서 소개한 DAGM 데이터셋 외에 매우 다양한 제조업 데이터에 transfer learning을 적용하고 있습니다. 오늘 소개드린 내용이 다양한 도메인에 transfer learning을 적용하려는 독자분들에게 도움이 되었으면 좋겠습니다. 혹시 본 글에서 다루지 못한 자세한 내용이 궁금하신 분들은 [10]를 참고해주시기 바랍니다. 감사합니다.
참고자료
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012): 1097-1105.
[2] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, T. Darrell, Decaf: A deep convolutional activation feature for generic visual recognition, in: Proc. of the International Conference on Machine Learning, 2014, pp. 647–655.
[3] M. D. Zeiler, R. Fergus, Visualizing and understanding convolutional networks, in: Proc. of the European Conference on Computer Vision, 2014, pp. 818–833.
[4] A. S. Razavian, H. Azizpour, J. Sullivan, S. Carlsson, Cnn features off-the-shelf: An astounding baseline for recognition, in: Proc. of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2014, pp. 512–519.
[5] M. Oquab, L. Bottou, I. Laptev, J. Sivic, Learning and transferring mid-level image representations using convolutional neural networks, in: Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 17171724.
[6] R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in: Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 580–587.
[7] J. Yosinski, J. Clune, Y. Bengio, H. Lipson, How transferable are features in deep neural networks?, in: Proc. of the Advances in Neural Information Processing Systems, 2014, pp. 3320–3328.
[8] Heidelberg Collaboratory for Image Processing, Weakly supervised learning for industrial optical inspection, https://hci.iwr.uni-heidelberg.de/node/3616, [Online; accessed 19-October-2019] (2007).
[9] Kim, Seunghyeon, et al. “Transfer learning for automated optical inspection.” 2017 International Joint Conference on Neural Networks (IJCNN). IEEE, 2017.
[10] Kim, Seunghyeon, Yung-Kyun Noh, and Frank C. Park. “Efficient neural network compression via transfer learning for machine vision inspection.” Neurocomputing 413 (2020): 294-304.
[11] P.P. Brahma, D. Wu, Y. She, Why deep learning works: A manifold disentanglement perspective, IEEE Trans. Neural Networks Learn. Syst. 27 (10) (2016) 1997–2008
[12] Y. Bengio, G. Mesnil, Y. Dauphin, S. Rifai, Better mixing via deep representations, in: Proc. of the 30th International Conference on Machine Learning, Vol. 28, 2013, pp. 552–560.
[13] Y. Bengio, A. Courville, P. Vincent, Representation learning: a review and new perspectives, IEEE Trans. Pattern Anal. Mach. Intell. 35 (8) (2013) 1798–1828.